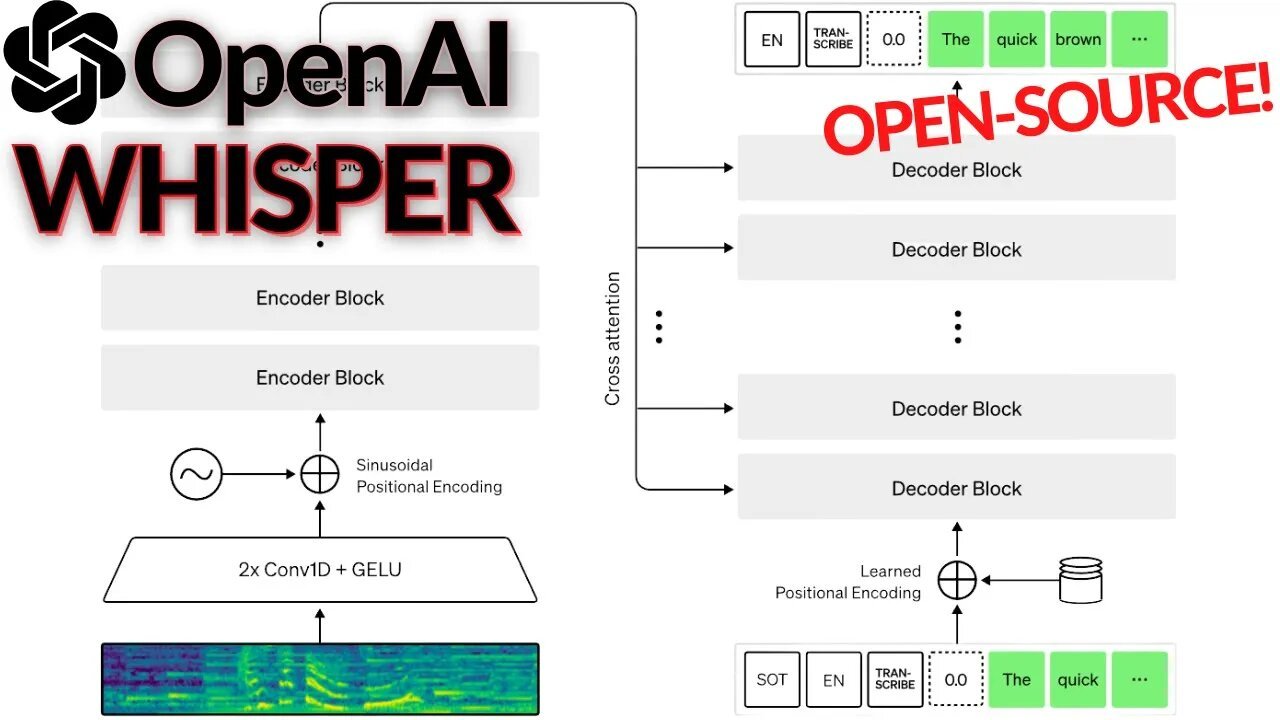

What is OpenAI Whisper API?
OpenAI Whisper API is a state-of-the-art speech-to-text platform designed to provide highly accurate transcription and translation services. Built on OpenAI’s advanced neural network architecture, Whisper excels in processing audio input to generate precise, context-aware text output. Ideal for developers, businesses, and content creators, the Whisper API supports multiple languages and accents, making it a versatile tool for applications such as transcription services, multilingual customer support, and accessibility enhancements.
Key Features
- Highly Accurate Transcription
Convert audio files into text with exceptional accuracy, even in noisy environments or with diverse accents. - Multi-Language Support
Transcribe and translate audio in numerous languages, enabling global communication and accessibility. - Real-Time Speech Recognition
Process audio in real-time for live transcription in meetings, webinars, and other time-sensitive applications. - Context-Aware Transcriptions
Leverage advanced neural networks to produce contextually accurate text, improving the quality of transcripts and translations. - Translation Capabilities
Automatically translate speech into other languages during transcription, supporting multilingual use cases. - Customizable for Applications
Fine-tune the API to align with specific industry requirements, from media production to customer service. - Scalable Performance
Handle high volumes of audio data efficiently, making it suitable for enterprises and large-scale deployments. - Secure and Reliable
Designed with robust security protocols to ensure data privacy and compliance with industry standards.
API Technology Highlights
- Neural Network-Based Model
Powered by a deep learning architecture optimized for speech recognition and translation. - Wide Audio Format Support
Compatible with multiple audio formats, including WAV, MP3, and others, ensuring seamless integration. - Noise Robustness
Handles challenging audio environments, including background noise, making it suitable for diverse real-world scenarios. - Real-Time and Batch Processing
Offers flexibility to process audio in real-time or in batches, depending on the application needs. - Cloud-Optimized Deployment
Easily deployable on cloud platforms for scalable and reliable performance across multiple regions.